 Paddle Billing
Paddle Billing ProfitWell Metrics
ProfitWell Metrics

Join our newsletter for the latest in SaaS
Building digital software that is distributed on mass scale comes with layers of complexity, some that can cause failure, some that cause disruption.
While we can’t control or avoid failures in engineering, we can control the impact radius of the failure and optimise the time to recover and restore the systems. How? Purposefully trying out as many failures as possible to test your confidence in the system’s resilience.
Chaos testing is key to our engineering practices at Paddle, so we wanted to share some of the best practices we use, the experiences we’ve had, and why chaos testing should form part of your routine practices.
What is chaos engineering?
Chaos engineering is a practice to introduce intentionally controlled chaos into a system, with the goal of identifying weaknesses and increasing the resilience of your system.
When we have microservices, the interactions between the services might generate unexpected scenarios, even if the services are working properly. These unexpected scenarios might then generate a production issue.
The diagram below shows an example of running chaos engineering in a system with different micro-services.
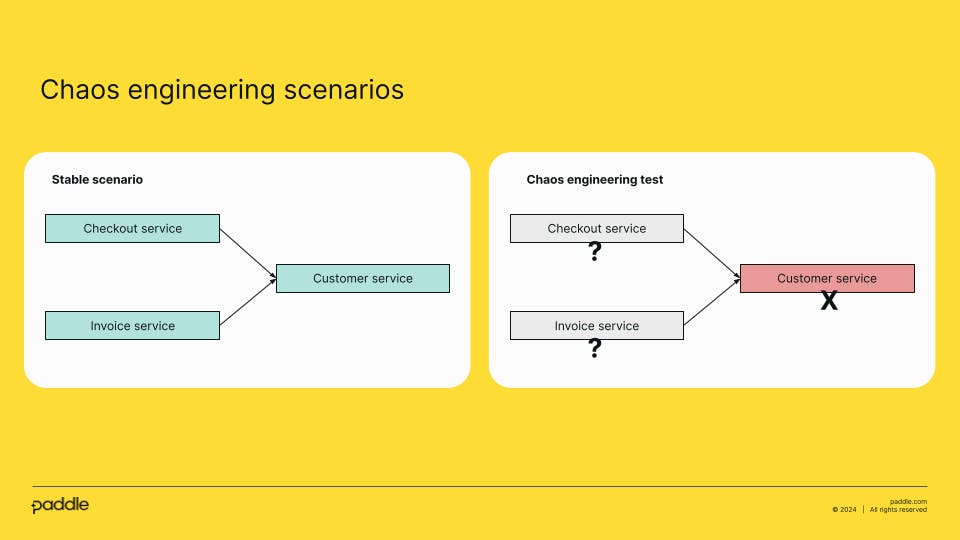
Let’s imagine a system where two services depend on another one. In this case, Checkout and Invoice are two independent services that call Customer service. An example of running chaos engineering in this system would be if Customer service is not available.
During chaos engineering tests, we want to understand how Checkout and Invoice services will behave if Customer service is down.
Considerations before you get started
As an engineering team we have the responsibility to test our systems, know the behaviour of them, and increase the resilience of the production environment.
A requirement before you get started is to identify all the dependencies between your services. This will help you to understand the current dependencies, and identify which part of your system you can introduce chaos.
While chaos engineering test is a generic concept, depending on your system and priorities, you’ll need to run different kinds of scenarios. For example, it might be related to downtime, network connections, malformed responses, timeouts, cloud provider failures and so on.
A more complex scenario might be a system where you call an external service, and in the chaos engineering tests, you test the behaviour of the system if the external system returns timeouts.
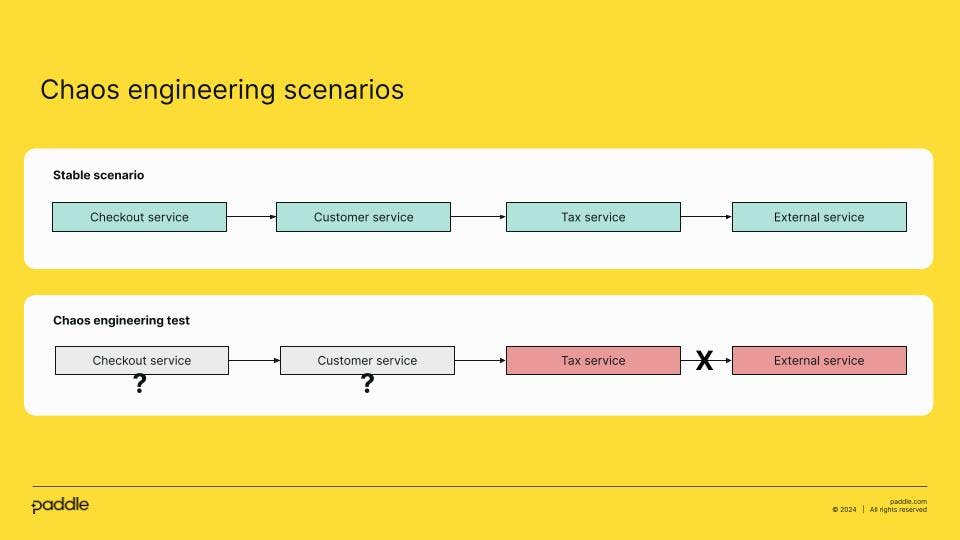
In our Paddle example, to simulate this scenario and run the tests, we need to update the Tax Service and simulate a timeout from the external service. Once we run the experiment, we need to investigate how Checkout and Customer Service respond. Are the services down? Which timeout are the systems using in the client? How many retries are defined in the client?
Chaos engineering tests are going to help us to ask these questions and improve the resilience of our systems.
Running a chaos engineering test
When we run chaos testing, it should be a one time testing round, done periodically. Your team of engineers should be constantly finding hypotheses to test, to improve overall performance of the systems.
In the following diagram we show the the different steps to follow:
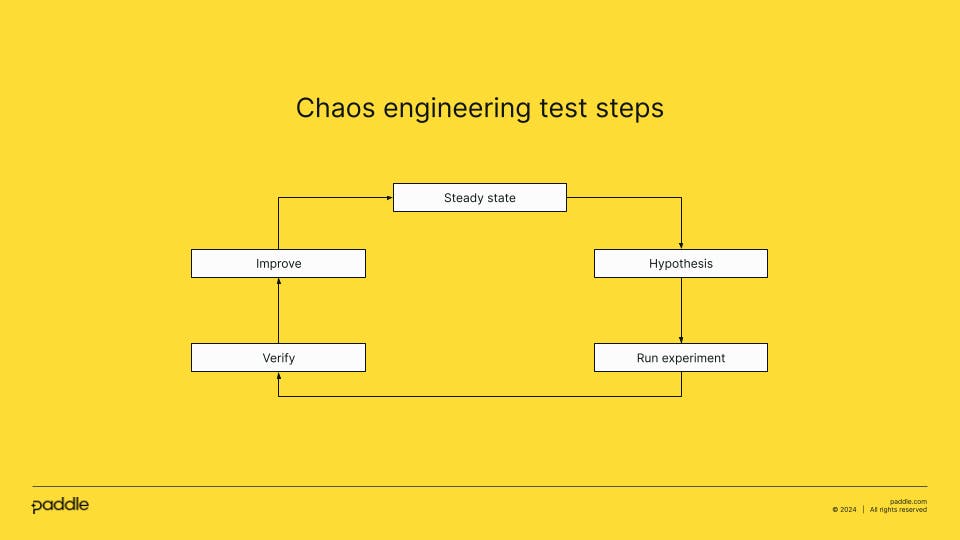
- Steady state: The point in time when your services are stable because the variables that impact it are constant or unchanging. Now is the time to identify all the dependencies between your services.
- Hypothesis: After identifying the different dependencies between your services, create different hypotheses where you think an unplanned state could generate a potential issue to your service. When you work to prepare these hypotheses, you need to have a global vision of all your services, as the unexpected behaviour of one service might impact other parts of your system. Once you identify where and how you want to introduce the chaos into your system, consider all the potential behaviours given that specific scenario.
- Run the experiment: Prepare the systems and the code to run the planned experiment. It is very important to run the experiment in a controlled environment, and you should notify all users of the environment about this testing. The most common environment where you can run the experiment is development or staging. Remember to add logins to your service so you can debug and verify later the behaviour of the systems.
- Verify: Once you finish the experiment, check the logs of all the involved services to see the behaviour of your systems. Compare the results with the hypotheses you put forth in the beginning.
- Improve: As you introduced some chaos in the system, you might get a different behaviour than expected. In this case, put together an improvement plan for your systems, and discuss with your team how to prioritise each improvement.
How to organise testing rounds
As chaos testing is crucial to helping us identify potential errors, we began running these tests early on at Paddle. It spans all of Paddle Billing’s microservices, involving all engineering teams.
Here’s an outline of how we run it at Paddle.
To run the tests properly, each engineering team nominated an owner to prepare their own micro-services for testing. The owner also prepared the different scenarios and the changes in the code required to run the tests.
This way, we got all the engineering teams involved in testing all our planned scenarios. As each owner was present during the testing rounds, this exercise also improved the understanding teams had of other services.
During the tests we focused on different scenarios, specifically downtime of a specific service, timeouts and malformed responses. These scenarios help us to test in detail the behaviour of the system when we have a timeout or other service is not available.
With this strategy, we successfully tested all the micro-services and planned scenarios, involving ten different engineering teams.
The upside of embracing chaos
Chaos engineering tests provide us an approach to build and maintain robust and reliable systems for Paddle Billing’s microservices, ultimately reducing the risk of failures and enhancing Paddle’s resilience.
From our work at Paddle, here are some of the benefits of running chaos testing rounds:
- Identifying unexpected behaviours: This practice gives us an opportunity to learn, in a controlled environment, how our systems behave in unexpected scenarios.
- Enhanced fault tolerance: With a better understanding how the system behaves in different failure conditions, engineers can take steps to make it more fault-tolerant and resilient.
- Early detection of system weaknesses: During these tests, the system is not operating under normal conditions. It allows us to identify weaknesses early to prevent future issues or outages.
- Reduced downtime: As the team continues to identify and learn of potential failure scenarios, it allows us to improve incident response times.
- Increased collaboration between teams: As these tests are executed various parts of our systems, it helps to increase the expertise and collaboration between the engineering teams.
The next phase of chaos engineering at Paddle
As we are constantly improving and adding new features to Paddle Billing, we want to empower each engineering team to run their own chaos engineering tests, giving more independence and agility to the teams.
We’re creating an internal package, where all the microservices are going to use, with the benefits:
- Each team doesn’t need to implement in their own way the Chaos Engineering tests.
- As all microservices are going to use the same package, all engineers are going to understand how it works and they can run testing rounds without depending of other teams.
- In the future we can automate the Chaos Engineering tests across all microservices in the same way, as all microservices are going to implement the same package.
Since we began building Paddle Billing, our team has consistently implemented chaos engineering tests to our systems. Today, it’s a process everyone is familiar with and a key part of our team’s culture.

Take the headache out of growing your software business
We manage your payments, tax, subscriptions and more, so you can focus on growing your software and subscription business.
